Yixin Technology focuses on AI
Data storage solutions, we help customers master the key to unlocking the intelligent future. Through precise and efficient AI storage Infra solutions, we assist you in seizing the initiative in the future race.
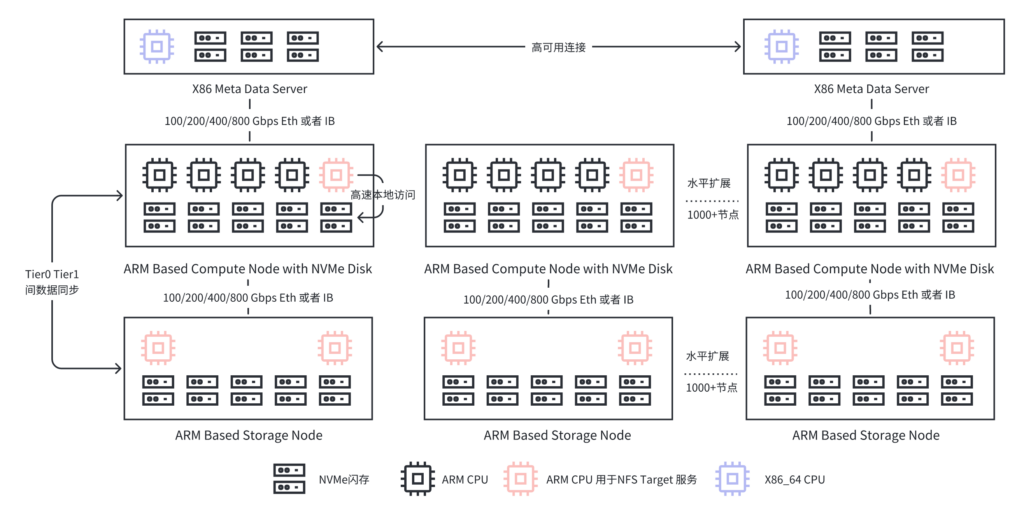
Make local storage on GPU nodes great again with Tier 0
The storage space on GPU nodes is getting larger and larger with the iteration of hardware, and it will become mainstream in 2025
GPU servers are already capable of supporting 100TB of local NVMe capacity, and this figure is expected to reach 2PB by 2026. The local storage space of Gpus is also experiencing a 1,000-fold increase in Scaling
Law.
How can we make better use of this part of the space? The answer is exactly what is discussed in this articleLarge-scale GPU cluster Tier
Solution
Hammerspace and Yixin Technology have officially announced their collaboration
SAN Mateo, Calif. - March 5, 2025 - The company that planned The Next Data Cycle
Hammerspace announced today the establishment of a strategic partnership with China. Yition.ai is dedicated to enabling ultra-large-scale AI
Leaders with accessible and efficient infrastructure.
This collaboration combines Hammerspace's proven high-performance global data platform for object and file storage with Yition.ai
Combined with its mission, it aims to completely transform the economy and accessibility of AI storage for cloud providers, high-performance computing, and hyperscale providers to use AI
The large amount of unstructured data generated provides new storage and data orchestration strategies.
Hammerspace has joined hands with Yixin Technology to create an ultra-large-scale AI storage solution for China
Hammerspace announced today a strategic partnership with Beijing Yition.ai Technology Co., LTD., a leading Chinese enterprise. Yixin Technology is committed to achieving ultra-large scale
The AI infrastructure is more accessible and operates efficiently.
This collaboration combines Hammerspace's mature high-performance global data platform (object and file storage) with Yixin Technology to reduce AI
The combination of storage costs and the goal of enhancing usability jointly enables cloud service, high-performance computing, and hyperscale cloud service providers to address AI
The massive unstructured data generated provides brand-new storage and data orchestration solutions.
The cooperation between the two sides can be described as a powerful alliance.
The DeepSeek methodology reconstructs the AI infrastructure, and Yixin Technology achieves a breakthrough in the AI Infra software and hardware integration architecture.
Currently, domestic companies in the AI Infra field are centered around DeepSeek
The series of inspirations brought about are also being considered for better solutions for the next step of large model training and optimization. Yixin Technology is one of them.
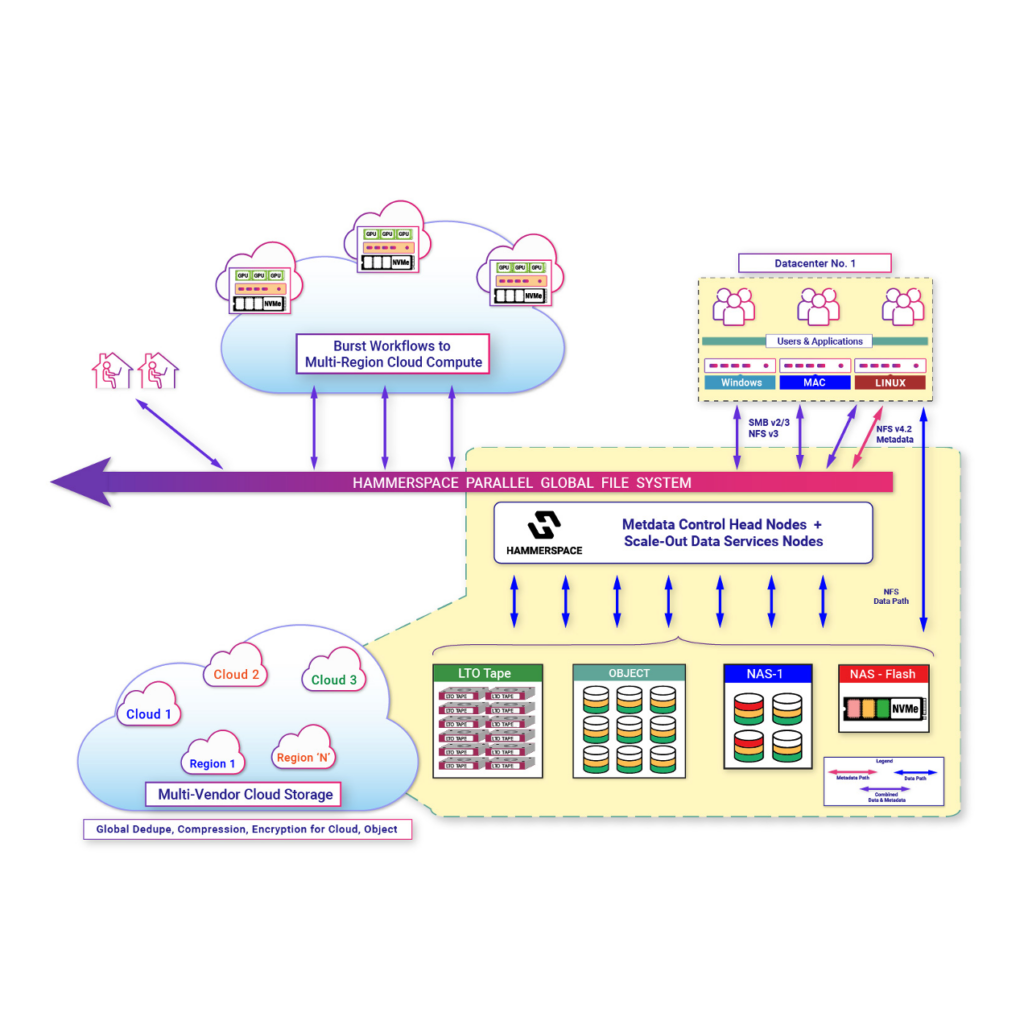
Data flow across infrastructure | Seamless connection between cloud and IDC data centers | High-speed large model all-in-one machine | Open protocols
Fully localized service
Simplify procurement and delivery for the AI era
Ecological openness and win-win cooperation
Focus on solving data storage problems in the AI era
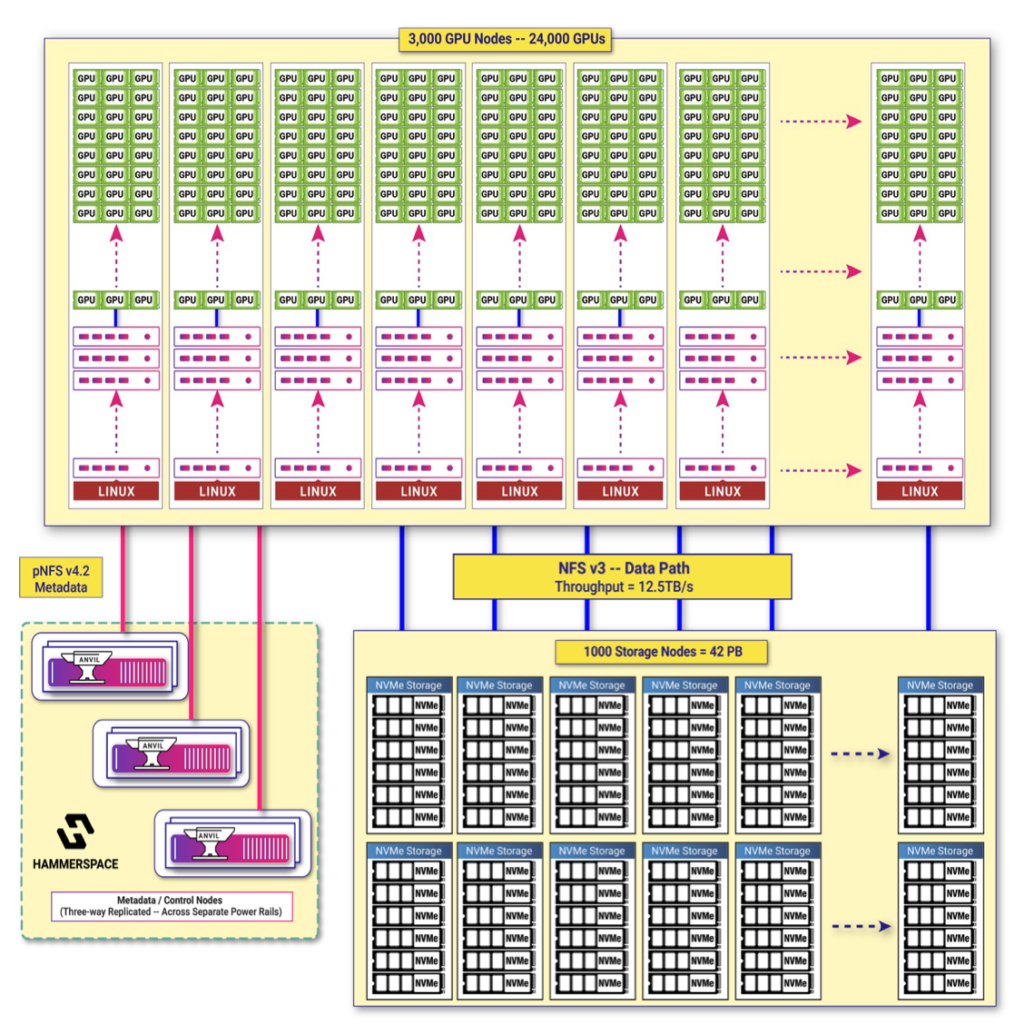
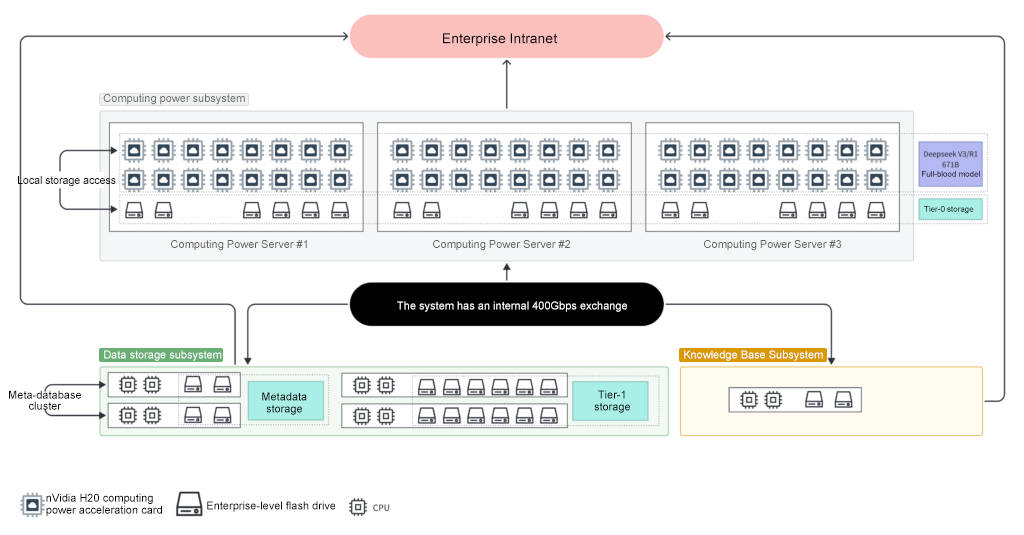
How to provide data for 24,000 GPU training tasks?
Over 1000 storage nodes
Super Scale-Out, 0 performance degradation
It is completely based on standard hardware and does not require custom hardware
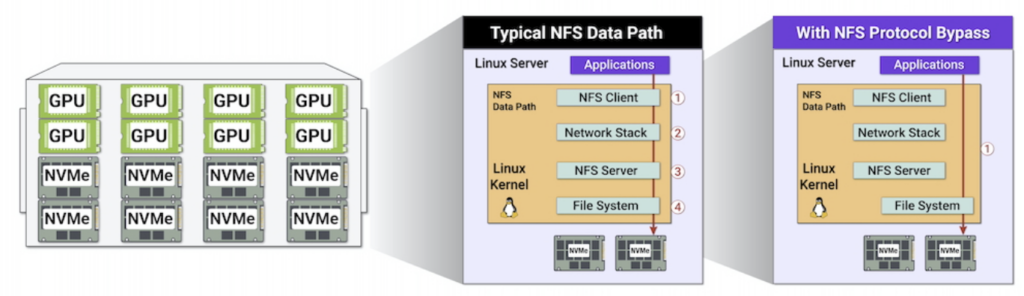
Direct access to the standard Kernel pNFS storage protocol
No client-side contamination
The reading speed of all datasets is 10 times, and the aggregated reading bandwidth is 12.8TB/S
How to provide data collaboration services for thousands of game developers worldwide?
The computing and storage resources required by a certain customer are spread all over the world.
The development team needs to seamlessly utilize burst computing power, data centers and cloud storage, as well as the ability to quickly allocate resources to support rapid iteration.
The Global NameSpace solution provides cross-cloud and cross-data center data flow without human intervention, reducing data circulation costs by 80% and significantly improving work efficiency
How do start-up semiconductor companies manage their rapidly growing businesses and data?
The software business of a certain EDA enterprise has grown by 150% annually, and the number of employees has increased fourfold. Its office locations are distributed in Beijing, Wuhan, Shenzhen and Chengdu.
Traditional NAS storage cannot smoothly match the rapid growth of business, cannot be flexibly delivered, cannot increase capacity and performance on demand, and cannot handle increasingly complex multi-location data management, COPY is rampant, and costs are out of control.
Yixin customized solution, achieving 10 times the performance and 10 times the capacity, replaces the existing solution, stores and synchronizes millions of test cases, automatically switches between hot and cold data, realizes access to three R&D centers, and automatically manages and synchronizes data versions.
Let the local DeepSeek V3/R1 take off at full capacity
Demand
Top domestic red-circle law firms are in urgent need of providing DeepSeek V3/R1 based services for nearly a thousand lawyer partners
The service addresses the re-exploration of the privacy value of internal materials and supports daily business needs such as document generation, article retrieval, and legal logic reasoning.
Users hope that the hardware investment has a sufficiently long life cycle, maximizes the investment value, and can provide good ecological compatibility, simplify delivery to the greatest extent, and be adapted to the application scenarios of legal work.
Plan
Yixin offers a turnkey solution for large model integrated clusters and integrated storage and computing, perfectly meeting customer needs:
It offers a throughput capacity of 4,000 Tokens per second
KV-Cache Tier0 local access latency <5μs
The throughput has increased by 50% to 135%,QPS has increased by more than 30%+
Hardware costs are reduced by 20%,The complexity of operation and maintenance is halved
An independent and controllable integrated solution for storage and computing
Localized supply | Independent control | "storage + computing" integration | Zero "risk" in the supply chain
Full-stack autonomy and controllability are achieved. The CPU, NVMe, network card, switch, and even storage chips all adopt domestic hardware to meet the mainstream performance business requirements, avoid supply risks, and ensure timely delivery.
Technological innovation
Yixin Technology focuses on technological innovation, driving the progress of the ecosystem through underlying innovation, connecting different links in the ecosystem chain, and solving customers' pain points.
Data integration driven by pNFS
In 2008, pNFS
Introduced as an optional feature in NFSv4.1, it brings the concepts of parallel access and higher scalability to the NFS protocol. It has been continuously enhanced and improved in subsequent RFCS, such as NFSv4.2
This version further improves pNFS, addressing some issues existing in pNFS 4.1, enabling it to provide better performance in a more efficient and scalable manner.
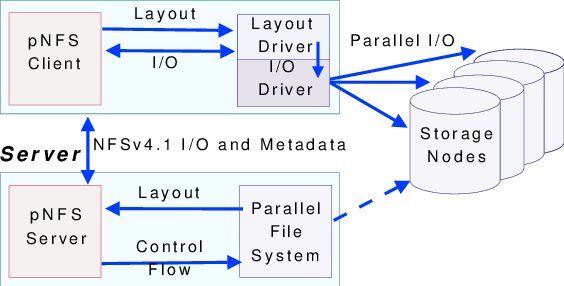
pNFS in the standard
Based on the NFSv4 architecture, it has been expanded, mainly adding layout drives, I/O drives and file layout retrieval interfaces. Specifically as follows:
Layout drive: Responsible for understanding the file layout of the storage system and mastering all the information required to access any byte range of files. It will come from pNFS
The read and write requests from the client are converted into I/O requests that can be understood by the storage device.
I/O drive: It mainly performs I/O operations, such as iSCSI, SunRPC and other storage nodes, to achieve data transmission between the client and the storage device.
File layout retrieval interface: It is used for the client to obtain file layout information, enabling the client to directly communicate with the storage device and perform data reading and writing after obtaining the file layout, without having to go through the server for relay each time.
The main advantages of the pNFS protocol are:
Linear scalability
By separating metadata from data communication, the client can communicate in parallel with multiple storage devices, which can easily handle large-scale data storage and high concurrent access requirements. As the number of storage nodes and clients increases, performance will not decline significantly
Prepare high performance for model training
After obtaining the file layout, the client can directly access the storage device, reducing the server's relay overhead and improving the data transmission efficiency. In large-scale data reading and writing scenarios, such as high-performance computing and big data processing, it can significantly enhance the reading and writing speed
High flexibility
It supports multiple storage devices and layout types, and can adapt to different storage architectures such as block storage, file storage and object storage, making it convenient for users to select storage devices and configure storage systems according to their needs and costs
Extensive compatibility
Expand on the basis of NFSv4, retain the basic functions and semantics of NFSv4, and be consistent with the existing NFS
The client and server are compatible. Users can gradually introduce pNFS without the need for large-scale replacement or modification of the existing system.
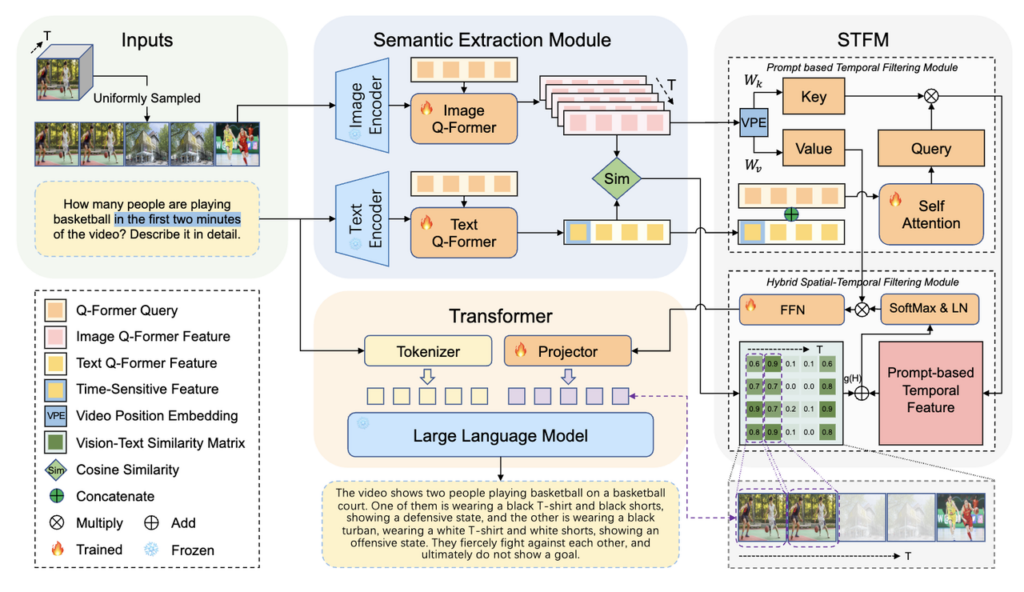
Video data simplification driven by multimodal LLM models
Yixin proposed FocusChat, a text-guided multimodal large language model. This model combines visual and text information through the Spatio-Temporal Filtering Module (STFM) to achieve explicit spatio-level information filtering and implicit time-level feature filtering, ensuring that visual tags are closely aligned with user queries and reducing the number of visual tags input into the language model. In practical applications, without reducing the accuracy, the number of visual tokens can be significantly reduced. Visual tokens can be reduced by an order of magnitude.