
降低存储成本,大幅降低功耗,将 GPU 提升至最佳性能,加快价值实现速度
大型AI 训练和推理 GPU 计算集群,需要非结构化数据处理支撑。而基础设施成本、空间和功耗限制已经成为瓶颈,传统的外部存储系统,如Lustre/GPFS集群,会增加成本,消耗资源,并且需要以月计的时间来评估、购买和部署存储解决方案。
同时,许多 GPU 服务器都有可用的本地容量,但这些容量没有被使用,孤立且不能与其他 GPU 服务器共享,并且无法提供足够的冗余和数据安全性。
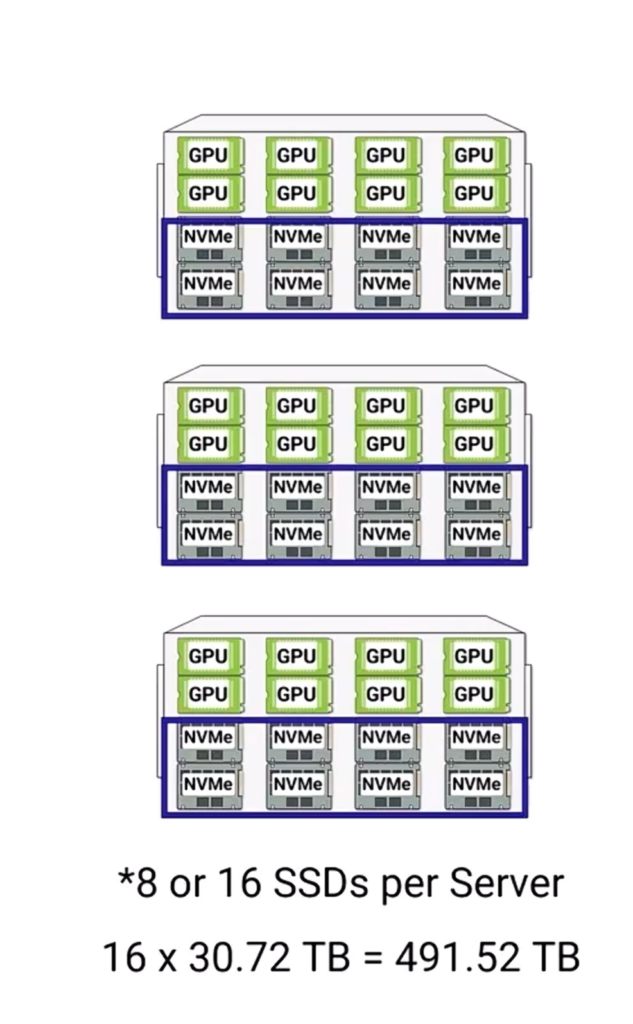
但是GPU节点上的存储空间,随着硬件的迭代,正变得越来越大,2025主流 GPU服务器已经能够支持100TB的本地NVMe容量,而这个数字,在2026年将会达到2PB,GPU本地存储空间,也在迎来1000倍增加的Scaling Law。
如何更好的利用这部分空间呢?——答案就是本文讨论的大规模GPU集群Tier 0解决方案了。
Tier 0 存储架构设计

释放限制存储资源,降低成本、功耗和空间
加快模型训练的Checkpoint写入,降低IO等待
让GPU集群专注于计算
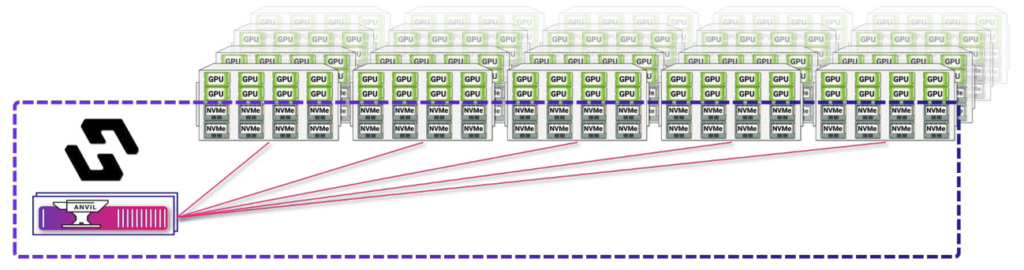
利用驿心科技的pNFS存储整合技术:
- GPU节点上的存储空间,将会被元数据服务器统一接管,并将所有GPU节点上的NVMe设备,合并成一个统一的存储空间。
- 例如128节点的算力集群,每台机器上有32TB的NVMe设备,则最终将得到4PB的独立存储,基本能够满足大部分的训练数据读写需求。
- 无需增加外置的对立存储设备,无需繁琐的布线、空间、网络规划。
得益于LOCALIO 的Linux内核特性,在GPU访问本地Tier 0存储设备时,NFS客户端会跳过整个网络协议栈,直接提供原生NVMe设备的IO性能,仅仅在必要时,进行跨节点的网络通讯。
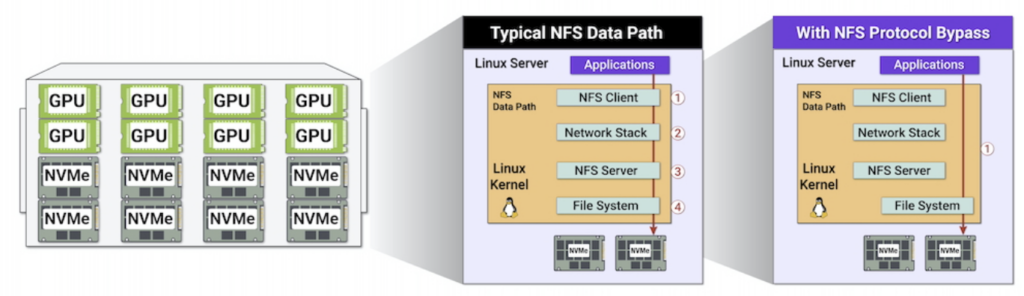
实际测试中,LOCALIO达成了接近本地存储性能的IO效率和表现。
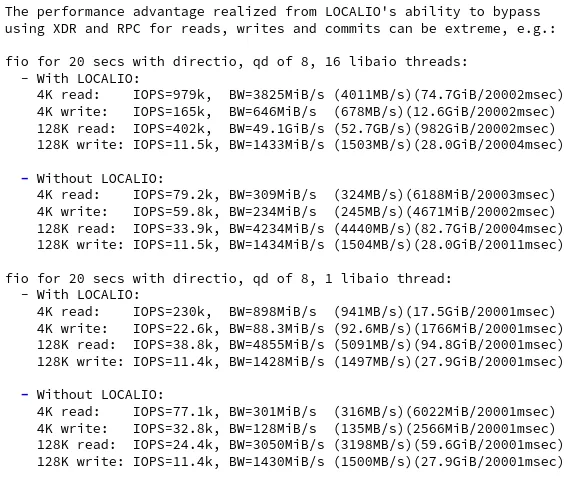
左侧benchmark数字说明,在启用了LOCALIO情况下,NFS协议提供了10x性能提升。
并且,驿心科技pNFS解决方案提供了Tier 0/1/2/3/4…/N的分级存储方案,能够整体融合各类不同存储介质和来源,直接实现多Tier的数据存储和流动一体解决方案,让数据流动。
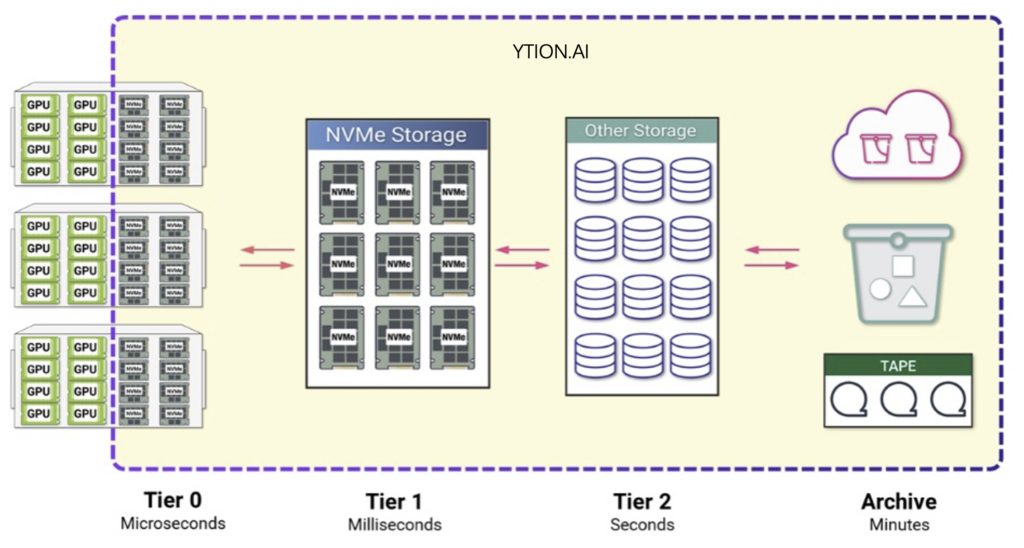
利用Tier 0,用户可以高效使用GPU节点本地存储,并利用Tier 0内数据冗余实现更高的数据可靠性,同时结合Tier 0/1/3… 等不同分级存储,实现高效的模型训练,和推理过程中的KV-Cache,这也是KV-Cache后端存储方案的最佳实践之一。