
在GTC 2025上,不出所料地,nVidia让全世界再次感受到作为这一轮大模型的技术领导者的深厚积累,挤爆牙膏的创新能力。
在本次的GTC众多猛料中,毫无疑问,Dynamo的发布,是Deepseek后,nVidia对于外界负面质疑的一次响亮的宣告。
认可Deepseek,拥抱Deepseek,借势Deepseek,强调开源模型带来巨大推理市场需求增长,nVidia向市场证明:在这一轮Deepseek掀起的狂潮中,自己依然是最大的赢家——而Dynamo正是这一主张的关键证据。
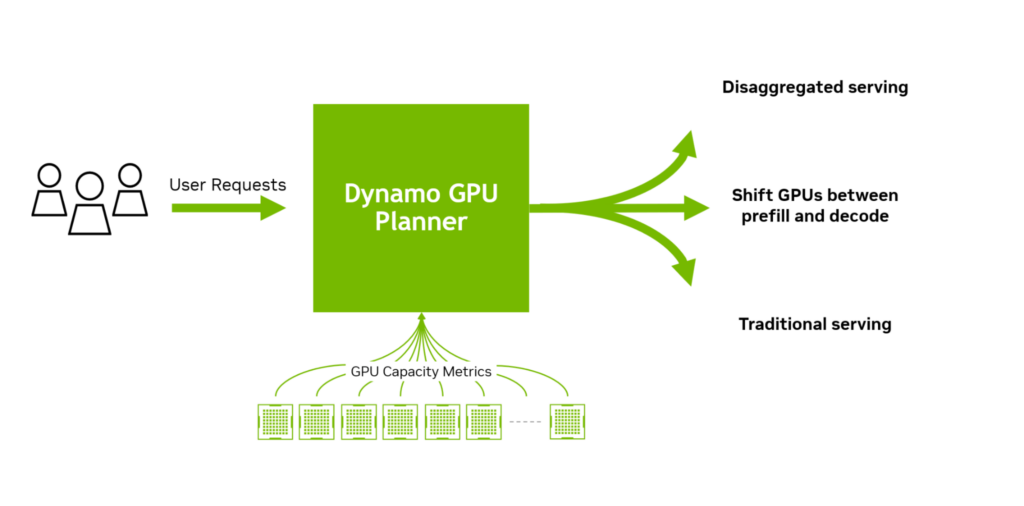
那么,什么是Dynamo?
NVIDIA Dynamo is a high-throughput, low-latency open-source inference serving framework for deploying generative AI and reasoning models in large-scale distributed environments.
NVIDIA Dynamo 是一款高吞吐量、低延迟的开源推理服务框架,用于在大规模分布式环境中部署生成式 AI 和推理模型。
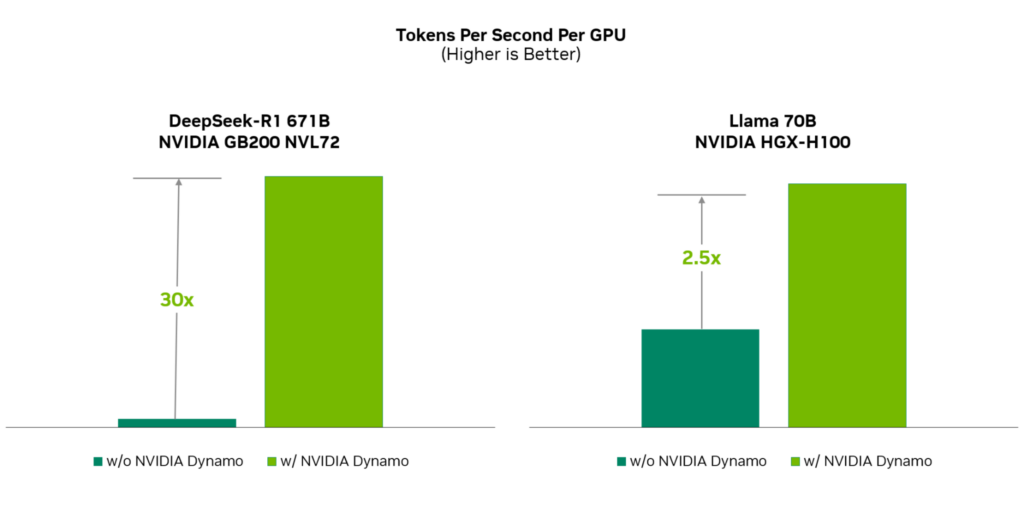
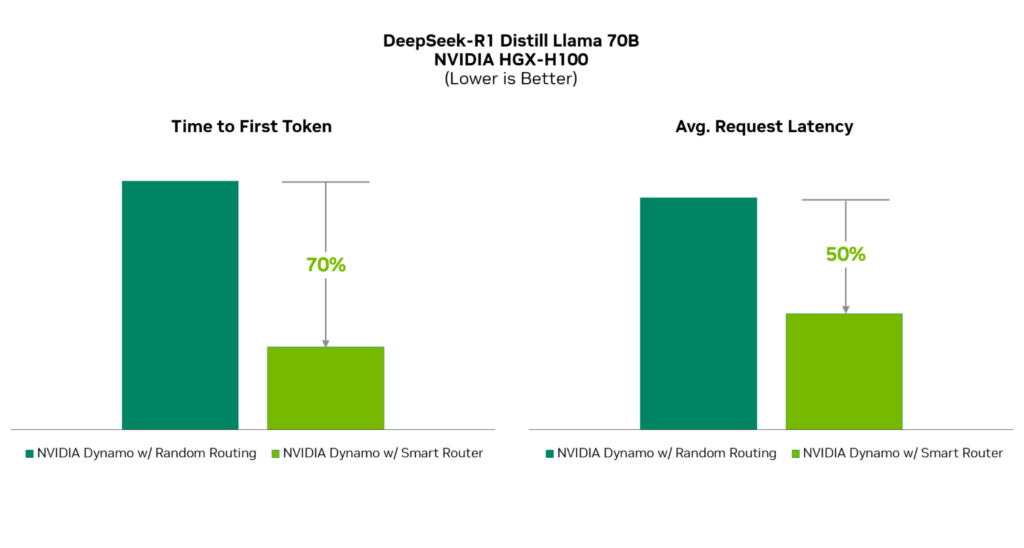
Dynamo结合了最新的LLM推理相关的技术进展,并深度结合nVidia生态中的硬件底层创新,实现了极为亮眼的性能提升,达到了:
30倍Deepseek R1 671B的推理吞吐效率
70%的首Token延迟降低
在强大而活跃的LLM社区面前,nVidia总是能够脱颖而出,遥遥领先,保持Tier-0级别的存在。
那么,Dynamo性能狂飙背后都有哪些秘密?
- 分离预填充和解码推理阶段,以提高每块 GPU 的吞吐量。
- 根据波动的需求对 GPU 进行动态调度,以优化性能。
- 采用大语言模型感知的请求路由,避免KV-Cache重新计算的成本。
- 加速 GPU 之间的异步数据传输,以减少推理响应时间。
- 在不同内存层级之间进行KV-Cache卸载,以提高系统吞吐量。
不难看出,KV-Cache在Dynamo的技术成功中,扮演了极为重要的角色。那么什么KV-Cache?KV-Cache在LLM的推理框架中扮演了什么角色?KV-Cache能带来什么样的收益呢?
——先从Dynamo的总体架构入手:
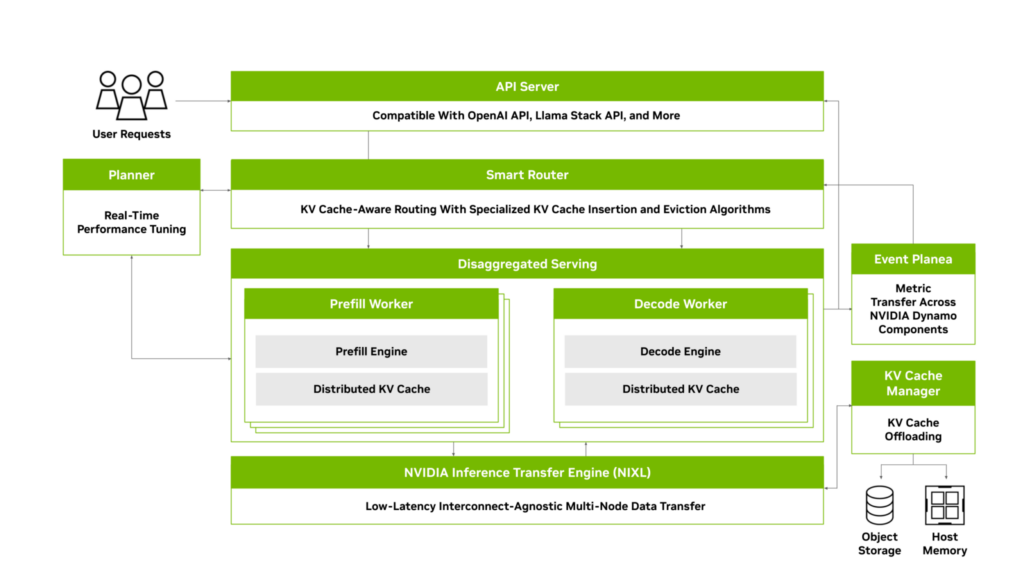
大致上,Dynamo框架中推理需要经历一下若干阶段:
- 用户发起API调用,提交Input,这里的Input可以是:
- 1)从0开始的全新对话,或者终止一断时间后恢复的对话
- 2)进行中的活跃对话。
- Input 经过 Smart Router,根据Input和对话的内容进一步确定请求的走向:
- 如用户提交Input为情况1),Prefill Worker会接手对话:
- 如此时Input能够命中KV-Cache,则整个计算可以被跳过,直接从KV-Cache中加载,如果无法命中KV-Cache(例如模型版本更新,或者由于容量问题,KV-Cache被抛弃),则重新计算Attention,输出第一个Token,并将结果写入KV-Cache,此时按照调度规则,后续的Token输出,会由 Decode Worker接管。
- 如用户提交Input为情况2):则直接进行计算,依然会尝试读/写KV-Cache,如命中KV-Cache,则也会直接加载KV-Cache,省略计算步骤,并给出下一个Token。
- 如用户提交Input为情况1),Prefill Worker会接手对话:
通过以上简单的流程描述,可以看出,KV-Cache用存储置换计算流程,从而极大的提高了推理过程中的吞吐效率,并极大的提高了长上下文情况下的首token延迟,对用户体验是极大的帮助。
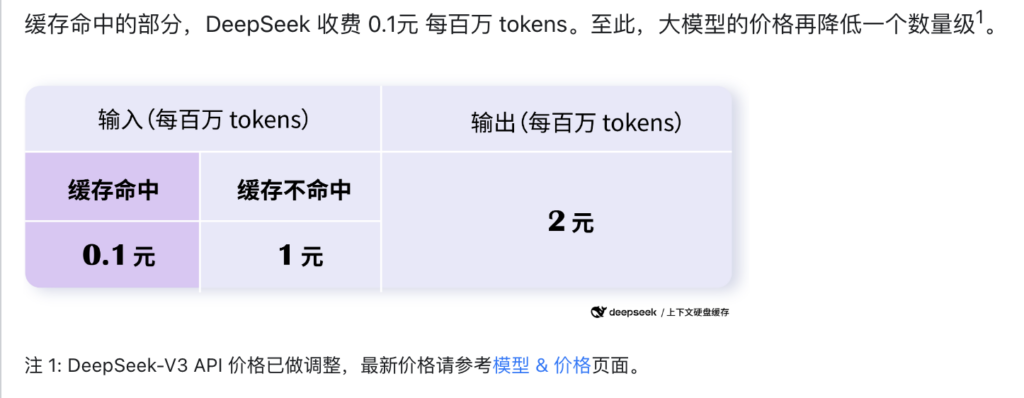
同时,显而易见的,KV-Cache命中率高低,是决定整个方案合理性和必要性关键因素,这里,不妨引用Deepseek披露的结果:
甚至,Deepseek更进一步,针对KV-Cache的这一特性,干脆直接结合商业模式,直接将Cache命中的收益,作为API服务的价格优惠返还给客户:
驿心科技提供了业界最简单、易用的分布式KV-Cache后端服务,具备以下优势:
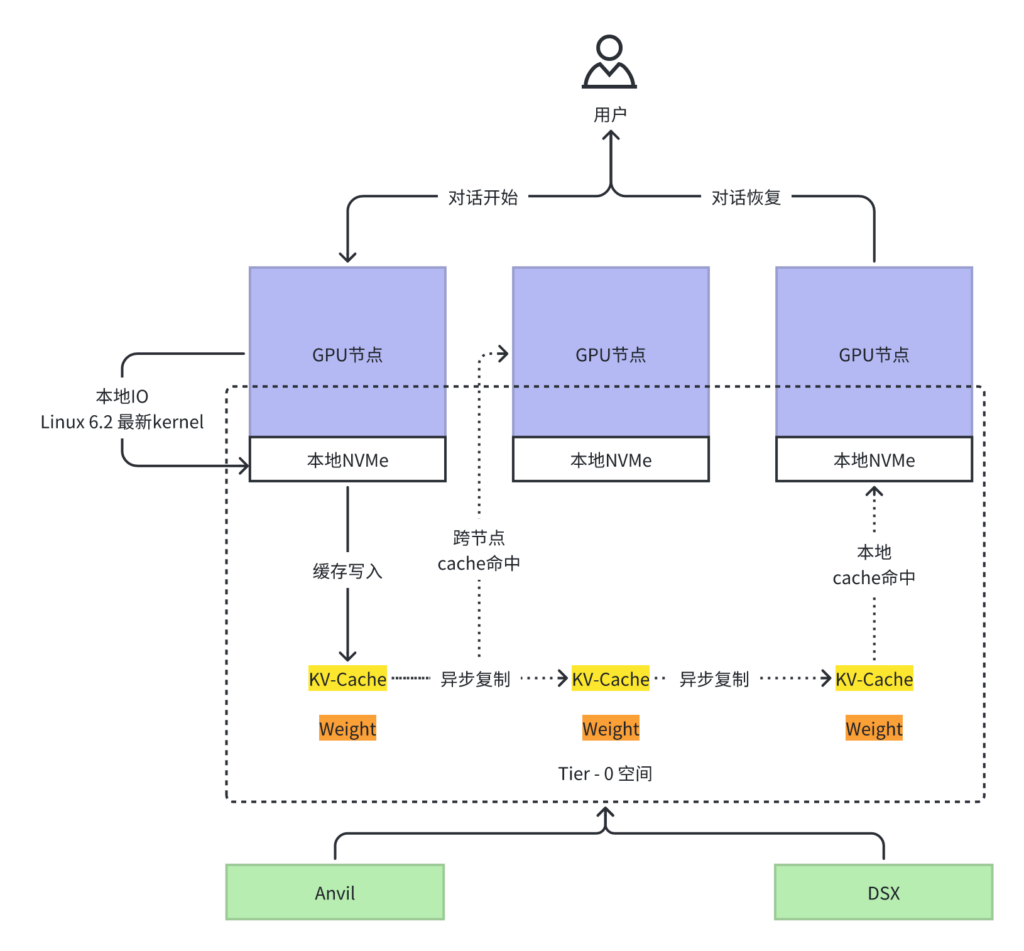
- 能够从让KV-Cache以Posix接口方式,无缝接入Dynamo等相关主流推理框架。
- 广泛的存储资源管理整合:支持:1)内存; 2) 本地NVMe; 3) 本地磁盘 3)异地OSS
- 充分利用推理GPU节点的高速本次磁盘,大幅度提升KV-Cache读/写 性能,最大可实现单节点 120GB/s 读/写速度
- 不同级别的Cache数据流动,由可编程的元数据实现配置变更管理,秒级实现Cache在不通设备中的流动和汰换。
- 支持存储设备接入的水平扩展,实现近乎无限容量的Cache空间扩展。